Scientific Programming with Python¶
http://gdfa.ugr.es/python¶
Outline¶
- Introduction to Python
- Python for science, where to begin?
- Python language
- Scientific libraries
Introduction to Python¶
What is Python?¶
Python is a modern, general-purpose, object-oriented, high-level programming language.
General characteristics of Python:
- clean and simple language: Easy-to-read and intuitive code, easy-to-learn minimalistic syntax, maintainability scales well with size of projects.
- expressive language: Fewer lines of code, fewer bugs, easier to maintain.
Advantages:¶
- The main advantage is ease of programming, minimizing the time required to develop, debug and maintain the code.
- Well designed language that encourage many good programming practices:
- Modular and object-oriented programming, good system for packaging and re-use of code. This often results in more transparent, maintainable and bug-free code.
- Documentation tightly integrated with the code.
- A large standard library, and a large collection of add-on packages.
- Packaging of programs into standard executables, that work on computers without Python installed.
Disadvantages:¶
- Since Python is an interpreted and dynamically typed programming language, the execution of python code can be slow compared to compiled statically typed programming languages, such as C and Fortran.
- Somewhat decentralized, with different environment, packages and documentation spread out at different places. Can make it harder to get started.
Python has a strong position in scientific computing
- Large community of users, easy to find help and documentation.
Extensive ecosystem of scientific libraries
- NumPy: numerical Python $\approx$ MATLAB matrices and arrays
- SciPy: scientific Python $\approx$ MATLAB toolboxes
- pandas: extends NumPy
- Matplotlib: graphics library
- Sympy: symbolic mathematics library
Scientific (and non-scientific) development environments available
- spyder: MATLAB-like environment
- Jupyter/IPython notebooks: environment for interactive and exploratory Python
- Rodeo: new Python environment for data science
- PyCharm: Python enviroment for developers
Great performance due to close integration with time-tested and highly optimized codes written in C and Fortran
Readily available and suitable for use on high-performance computing clusters
No license costs, no unnecessary use of research budget
Python for science, where to begin?¶

Why to choose Python 2?¶
- Python 3 is better, but some non-widespread science modules are still not compatible
- Differences between Python 2 and 3 are relatively minor
- Python 2 is actively supported. For example, Linux distributions and Macs are still using 2.x as default
Scientific-oriented Python Distributions¶
Provide a Python interpreter with commonly used scientific libraries in science like NumPy, SciPy, Pandas, matplotlib, etc. already installed. In the past, it was usually painful to build some of these packages. Also, include development environments with advanced editing, debugging and introspection features.
- Anaconda
- Cross-platform
- Supports Python 2 and 3
- Most widely adopted
- Canopy
- Cross-platform
- Only supports Python 2
- Python(x,y)
- Windows-only platform
- Only support Python 2

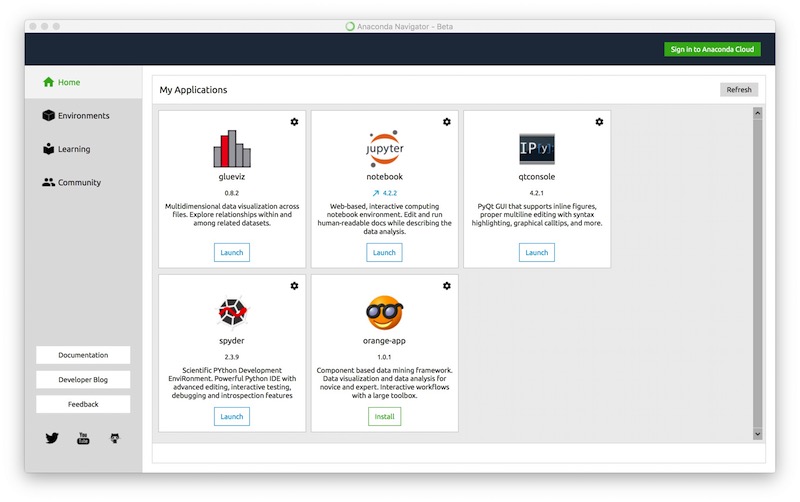
Anaconda navigator¶
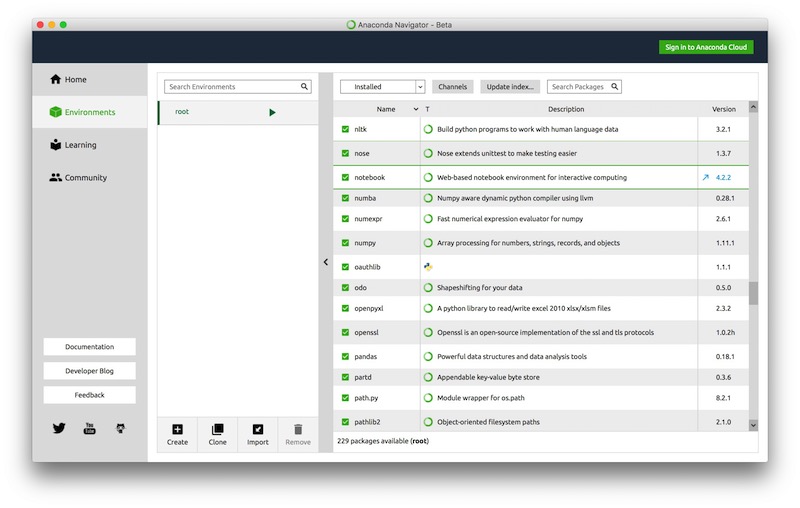
Anaconda navigator: installing new packages¶
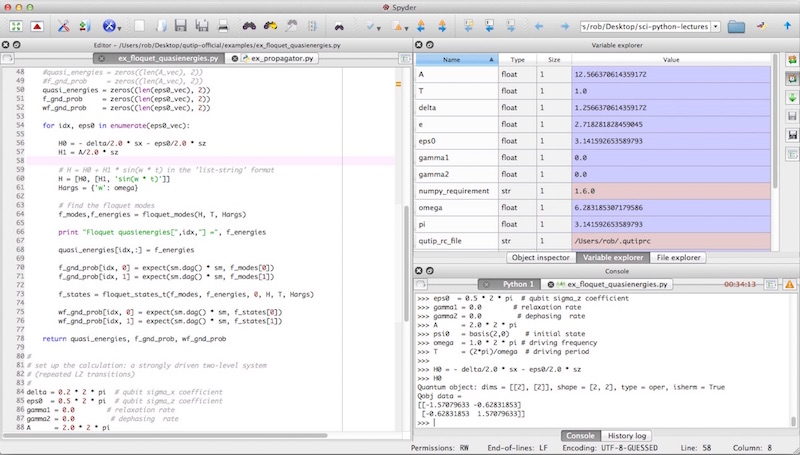
spyder¶
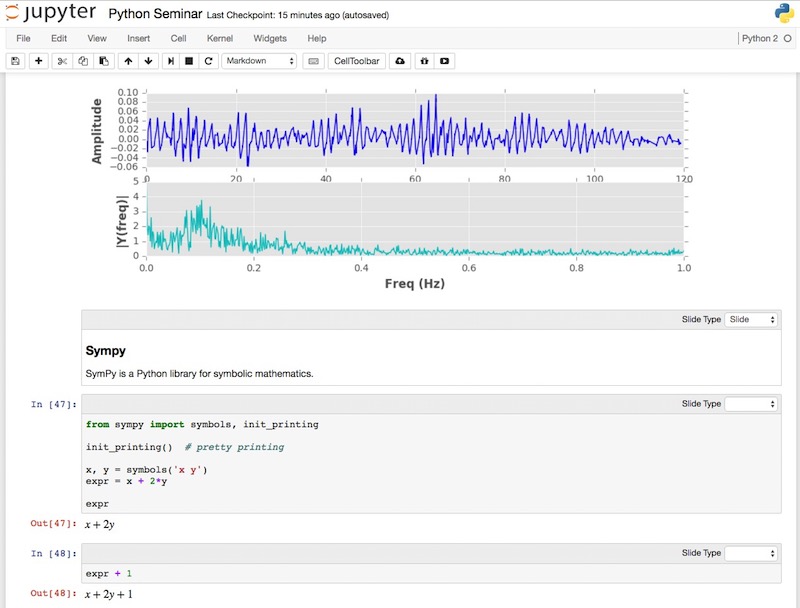
IPython/Jupyter notebooks¶
Rodeo (need to be installed separately from Anaconda)¶
PyCharm (need to be installed separately from Anaconda)¶

| Editor | Learning curve | Users | Benefits |
|---|---|---|---|
| spyder | pretty short | Matlab and R background | mature, many features |
| rodeo | pretty short | Matlab and R background | modern, essential features |
| IPython/Jupyter | smooth | teachers | interactive |
| PyCharm | moderate | developers | code quality |
Where to look for help?¶
- Official documentation: http://www.scipy.org/docs.html
- Usually included in development environments as contextual help:
- spyder: Ctrl+I (Windows) or Cmd+I (Mac)
- PyCharm: F1 (Windows/Mac)
- Rodeo:
?fin the console
- Be careful about code you get on the internet!

Python language¶
Using Python as a Calculator¶
2 + 2
17 / 3 # int / int -> int
from __future__ import division
17 / 3
Strings¶
prefix = 'Py'
word = prefix + 'thon'
# character in position 0
print word[0]
# characters from position 0 (included) to 6 (excluded)
print word[0:6]
Note¶
- 0-based indexing
- half-open range indexing: [a, b)
- print statement to get outputs
- line comments
Lists¶
# empty list
squares = []
# lists might contain items of different types
squares = ['cat', 4, 3.2]
# negative indices mean count backwards from end of sequence
print squares[-1]
# list concatenation
squares = squares + [81, 'dog']
# list functions
squares.remove(3.2) # remove the first ocurrence
squares.append('horse') # concatenation: same as +
print squares
a = ['a', 'b', 'c']
n = [1, 2, 3]
# it is possible to nest lists
# (create lists containing other lists)
x = [a, n]
print x
print x[0]
print x[0][1]
Simple code: Fibonacci series¶
a, b = 0, 1
while a < 10:
print a,
# the sum of two elements defines the next
a, b = b, a + b
Note¶
- indentation level of statements is significant
- multiple assignment
if Statements¶
x = -4
if x < 0:
x = 0
print 'Negative changed to zero'
elif x == 0:
print 'Zero'
elif x == 1:
print 'Single'
else:
print 'More'
for Statements¶
words = ['cat', 'window', 'defenestrate']
for w in words:
# len returns the number of items of an object.
print w, len(w)
Warning¶
Please avoid Matlab-like for statements
for w in range(len(words)):
print words[w], len(words[w])
range(stop)
Built-in function to create lists containing arithmetic progressions.
print range(10)
print range(0, 10, 3)
print range(0, -10, -1)
for i in range(4):
print 'cat',
words = ['cat', 'window', 'defenestrate']
for i, w in enumerate(words):
print i, w
Functions¶
def fib(n):
"""Build a Fibonacci series up to n.
Args:
n: upper limit.
Returns:
A list with a Fibonacci series up to n.
"""
f = [] # always initialize the returned value!
a, b = 0, 1
while a < n:
f.append(a)
# the sum of two elements defines the next
a, b = b, a + b
return f
# now call the function we just defined:
print fib(1000)
Functions: documentation strings (docstrings)¶
- Python documentation strings (docstrings) provide a convenient way of associating documentation with Python functions and modules.
- Docstrings can be written following several styles. We use Google Python Style Guide.
- An object's docsting is defined by including a string constant as the first statement in the function's definition.
- Unlike conventional source code comments the docstring should describe what the function does, not how.
- All functions should have a docstring.
- This allows to inspect these comments at run time, for instance as an interactive help system, or export them as HTML, LaTeX, PDF or other formats.


Functions: default argument values¶
def fib(n, s=0):
"""Build a Fibonacci series up to n.
Args:
n: upper limit.
s: lower limit. Default 0.
Returns:
A list with a Fibonacci series up to n.
"""
f = [] # always initialize the returned value!
a, b = 0, 1
while a < n:
if a >= s: # lower limit
f.append(a)
# the sum of two elements defines the next
a, b = b, a + b
return f
print fib(1000, 15)
print fib(1000, 0)
print fib(1000)
Functions: keyword arguments¶
print fib(1000, 15) # positional arguments
print fib(s=15, n=1000) # keyword arguments
Functions: returning multiple values¶
def fib(n, s=0):
"""Build a Fibonacci series up to n.
Args:
n: upper limit.
s: lower limit. Default 0.
Returns:
(f, l):
* ``f``: list with a Fibonacci series up to n.
* ``l``: length of Fibonacci series.
"""
f = [] # always initialize return values!
l = 0
a, b = 0, 1
while a < n:
if a >= s: # lower limit
f.append(a)
# the sum of two elements defines the next
a, b = b, a + b
l = len(f) # number of elements
return f, l
a, b = fib(1000)
print a
print b
c = fib(1000)
print c
Functions: importing external functions¶
import fibonacci # without .py extension
print fibonacci.fib(3)
from fibonacci import fib
print fib(3)
import fibonacci as f # alias
print f.fib(3)
Recommendation¶
The best way to import libraries is included in their official help
Some examples:
import math
import numpy as np
from scipy import linalg, optimize
import pandas as pd
import matplotlib as mpl
import matplotlib.pyplot as plt
import sympyCode Style¶
- Style Guide for Python Code: PEP8.
- Use only English (ASCII) characters for variables, functions and files. It is possible to use non-English characters in strings and comments by adding the following line at the beginning of each file:
# -*- coding: utf-8 -*-. - Name your variables, functions and files consistently: the convention is to use lower_case_with_underscores.
- We all use single-quoted strings to be consistent. Nevertheless, single-quoted strings and double-quoted strings are the same. PEP does not make a recommendation for this, except for function documentation where tripe-quote strings should be used.
datetime data type¶
The datetime module supplies classes for manipulating dates and times. Avoid converting dates or times to int (datenum or similar).
from datetime import datetime, date, time
# Using datetime.combine()
d = date(2005, 7, 14)
t = time(12, 30)
dt1 = datetime.combine(d, t)
print dt1
print dt1.year
from datetime import timedelta
dt2 = dt1 + timedelta(hours=5)
print dt2
timedelta([days[, seconds[, microseconds[, milliseconds[, minutes[, hours[, weeks]]]]]]])
All arguments are optional and default to 0. Arguments may be ints, longs, or floats, and may be positive or negative.
boolean data type¶
boolean values are the two constant objects False and True. In numeric contexts (for example when used as the argument to an arithmetic operator), they behave like the integers 0 and 1, respectively.
Nevertheless, other values can also be considered false or true:
- the following values are considered false: 0,
'',[],(),{},None - all other values are considered true, so objects of many types are always true
Scientific libraries¶
NumPy¶
NumPy’s main object is the homogeneous multidimensional array (ndarray). It is a table of elements (usually numbers), all of the same type, indexed by a tuple of positive integers. In Numpy dimensions are called axes. The number of axes is rank.
import numpy as np
# defining arrays and matrices
Z = np.array([1, 3, 4])
A = np.array([[1, 1],
[0, 1]])
B = np.array([[2, 0],
[3, 4]])
# selecting elements
print A[0, :]
# elementwise product with * operator!
print A * B
# matrix product
print np.dot(A, B)
from numpy.linalg import solve, inv # linear algebra
a = np.linspace(-np.pi, np.pi, 10)
print a
a = np.array([[1, 2, 3], [3, 4, 6.7], [5, 9.0, 5]])
print a
b = np.array([3, 2, 1])
print solve(a, b) # solve the equation ax = b
print inv(a)
print a.transpose()
ndim the number of axes (dimensions) of the array. In the Python world, the number of dimensions is referred to as rank.
shape the dimensions of the array. This is a tuple of integers indicating the size of the array in each dimension. For a matrix with n rows and m columns, shape will be (n, m). The length of the shape tuple is therefore the rank, or number of dimensions, ndim.
size the total number of elements of the array. This is equal to the product of the elements of shape.
dtype an object describing the type of the elements in the array. One can create or specify dtype’s using standard Python types. Additionally NumPy provides types of its own. numpy.int32, numpy.int16, and numpy.float64 are some examples.
Warning¶
When operating and manipulating arrays, their data is sometimes copied into a new array and sometimes not. For example, simple assignments make no copy of array objects or of their data.
Vectorization¶
Numpy arrays enable you to express batch operations on data without writing any for loops. This is usually called vectorization:
- vectorized code is more concise and easier to read
- fewer lines of code generally means fewer bugs
- the code more closely resembles standard mathematical notation
But:
sometimes it's difficult to move away from the for-loop school of thought
Pandas¶
Pandas is a newer package built on top of NumPy and pandas objects are valid arguments to most NumPy functions:
- fast and efficient Series (1-dimensional) and DataFrame (2-dimensional) heterogeneous objects for data manipulation with integrated indexing
- tools for reading and writing data from different formats: CSV and text files, Microsoft Excel, SQL databases, HDF5...
- intelligent label-based slicing
- time series-functionality
- integrated handling of missing data
import pandas as pd
# ignore the following commands
# just for the slides
pd.set_option("display.max_rows", 10)
pd.set_option("display.max_columns", 5)
simar = pd.read_table('WANA_2006008_Algeciras.txt',
delim_whitespace=True,
parse_dates= {'date' : [0,1,2,3]},
index_col='date', skiprows=70)
simar
read_table(...)
Read general delimited file into DataFrame.
delim_whitespace: boolean, default False. Specifies whether or not whitespace (e.g. ' ' or ' ') will be used as the sep.parse_dates: boolean or list of ints or names or list of lists or dict, default False boolean. dict, e.g. {‘foo’ : [1, 3]} -> parse columns 1, 3 as date and call result ‘foo’index_col: int or sequence or False, default None. Column to use as the row labels of the DataFrame.skiprows: list-like or integer, default None. Line numbers to skip (0-indexed) or number of lines to skip (int) at the start of the fileheader: int or list of ints, default ‘infer’. Row number(s) to use as the column names, and the start of the data. Default behavior is as if set to 0 if no names passed, otherwise None.
simar['Hm0'] # selecting a single column
simar[['Hm0', 'Tp']] # selecting several columns using a list
simar.iloc[0:3] # selecting rows by position
print simar.loc['1996-01-14 03:00:00'] # selecting rows by label
# selecting columns and rows
print simar.loc['1996-01-14 03:00:00', 'Hm0'] # selection by label
print simar.iloc[0, 0] # selection by position
print simar.ix[0, 'Hm0'] # mixed integer and label based selection
simar.iloc[:,0]
simar.describe()
SciPy¶
SciPy is a collection of mathematical algorithms and convenience functions built on the Numpy extension of Python.
- Clustering algorithms (
scipy.cluster) - Physical and mathematical constants (
scipy.constants) - Fast Fourier Transform routines (
scipy.fftpack) - Integration and ordinary differential equation solvers (
scipy.integrate) - Interpolation and smoothing splines (
scipy.interpolate) - Input and Output (
scipy.io) - Linear algebra (
scipy.linalg) - N-dimensional image processing (
scipy.ndimage) - Orthogonal distance regression (
scipy.odr) - Optimization and root-finding routines (
scipy.optimize) - Signal processing (
scipy.signal) - Sparse matrices and associated routines (
scipy.sparse) - Spatial data structures and algorithms (
scipy.spatial) - Special functions (
scipy.special) - Statistical distributions and functions (
scipy.stats) - C/C++ integration (
scipy.weave)
matplotlib¶
matplotlib is a library for making plots in Python. The main component of matplotlib is pylab which allow the user to create plots with code quite similar to MATLAB figure generating code. matplotlib has its origins in emulating the MATLAB® graphics commands.
# ignore the following command
# just for the slides
%matplotlib inline
import matplotlib.pyplot as plt
plt.figure(1, figsize=(10, 6))
plt.plot(simar.index, simar['Hm0'], 'b')
plt.xticks(rotation=30)
plt.title('Simar Algeciras')
plt.ylabel('$Hm_0$')
plt.savefig('wana.png') # save to file
plt.show() # display on screen

plt.style.use('ggplot') # pre-defined styles
plt.figure(2, figsize=(10, 6))
plt.plot(simar.index, simar['Hm0'], 'b')
plt.xticks(rotation=30)
plt.title('Simar Algeciras')
plt.ylabel('$Hm_0$')
plt.show()

plt.figure(3, figsize=(10, 6))
plt.subplot(311)
plt.plot(simar.index, simar['Hm0'], 'b')
plt.ylabel('$Hm_0$')
plt.xticks([])
plt.subplot(312)
plt.plot(simar.index, simar['Tp'], 'c')
plt.ylabel('$T_p$')
plt.xticks(rotation=30)
plt.show()

Fourier Transform (full code)¶
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
# Input data
df = pd.read_csv('T130_6_1_2.csv', sep=',',skiprows=2,
header=None, error_bad_lines=False, na_values='',
skipinitialspace=True)
df
# One-dimensional discrete Fourier Transform
y = np.fft.fft(df[1].dropna())
n = len(y)
y = y[range(int(n/2))]
t = np.linspace(0, 1, int(n/2)) # Frecuency generation
plt.style.use('ggplot')
# Signal plot
plt.figure(4, figsize=(10, 6))
plt.plot(df[5], df[6], '-c', label='v2')
plt.plot(df[0], df[1], '-.b', label='v1')
plt.xlabel('time (s)', weight='bold')
plt.ylabel('velocity (m/s)', weight='bold')
plt.legend(loc=2)
plt.xticks(rotation=70)
# Signal and spectral amplitude plots
plt.figure(5, figsize=(10, 8))
plt.subplot(511)
plt.plot(df[0], df[1], 'b')
plt.xlabel('Time', weight='bold')
plt.ylabel('Amplitude', weight='bold')
plt.subplot(512)
plt.plot(t, abs(y), 'c')
plt.xlabel('Freq (Hz)', weight='bold')
plt.ylabel('|Y(freq)|', weight='bold')
plt.show()


Sympy¶
SymPy is a Python library for symbolic mathematics.
from sympy import symbols, init_printing
init_printing() # pretty printing
x, y = symbols('x y')
expr = x + 2*y
expr
expr + 1
Derivative of $sin(x)e^x$
from sympy import diff, sin, exp
diff(sin(x)*exp(x), x)
Compute $\int(e^x\sin{(x)} + e^x\cos{(x)})\,dx$
from sympy import integrate, cos
integrate(exp(x) * sin(x) + exp(x) * cos(x), x)
Compute $\int_{-\infty}^\infty \sin{(x^2)}\,dx$
from sympy import oo
integrate(sin(x**2), (x, -oo, oo))